Synthetic Data Generation
By Kaspar Soltero
A method for generating large volumes of high-quality, richly labelled, synthetic soundscapes from limited real-world data. The method can be used to augment the size of training datasets for computational bioacoustics, as well as to automatically generate pixel-level training labels. We use a combination of high-quality real-world examples of animal vocalisations, background noise, and contaminating noise (anthrophony, geophony), to synthesise novel and realistic artificial soundscapes.
Our synthetic data generation method is segmented into two stages: Manual data gathering and soundscape synthesis.
Manual Data Gathering
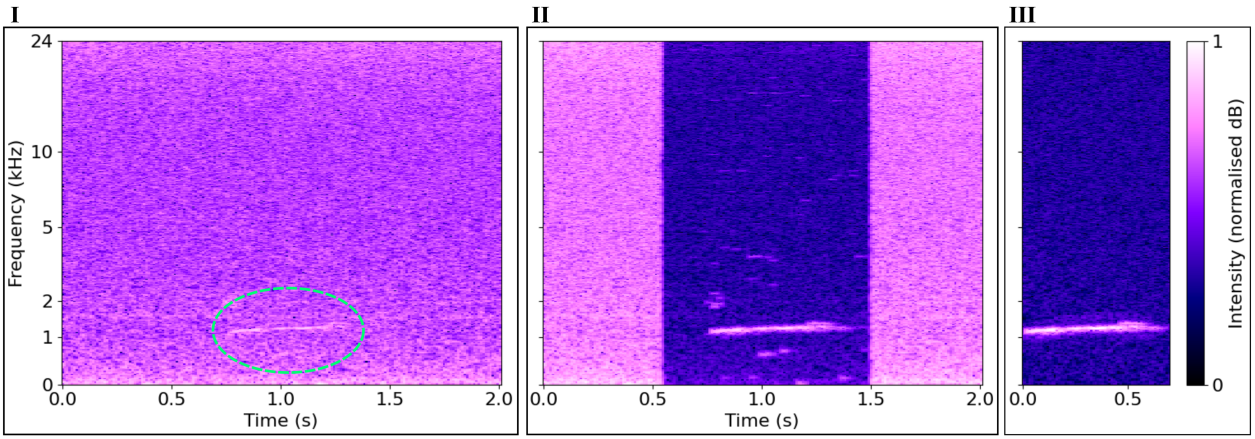
We start by precisely isolating vocalisations of interest from real soundscapes. Vocalisations with high SNR are precisely isolated from the surrounding soundscape. The floor spectrum is sampled from a nearby region of stationary background noise (I), used to perform spectral subtraction on the vocalisation (II), and manually mask-cropped (III). This results in an isolated sample with very low noise.
Repeating this process several times for each class of interest, as well as for examples of contaminating or confounding transient noises (e.g. aeroplanes, wind gusts), we obtain a bank of quality positive and negative samples. We also sample diverse background noise clips, with no vocalisations audible or visible in the time-frequency domain. Adding these to the positive and negative vocalisation examples, we curate a high-quality input dataset for soundscape synthesis. Soundscape Synthesis
The process of artificial soundscape synthesis from a set of high-quality real-world examples is as follows:
- A background noise sample is selected and cropped to the desired final duration.
- Some number of confounding 'negative' example sounds are selected, power-shifted, and their audio signals summed with the background noise.
- The chosen 'positive' target vocalisations are selected and processed one by one. For each vocalisation, a position in the soundscape is chosen (which may overlap with the soundscape's boundaries), and a placement attempt is started.
- Placement of the vocalisation is done in two passes. Firstly, the rectangular region where the vocalisation is to be placed is measured for its background power value. This is used to determine the minimum power level for augmenting the target vocalisation. The clean target vocalisation is then augmented, and a time-frequency pixel-level mask label is generated for the class. The two-stage process ensures that no vocalisation is too quiet to detect in the final soundscape.
- The final soundscapes and labels can be transformed into any suitable format for the training task, whether that be audio or spectrograms, from coarse file-level labels all the way to spectrogram pixel-level labels.
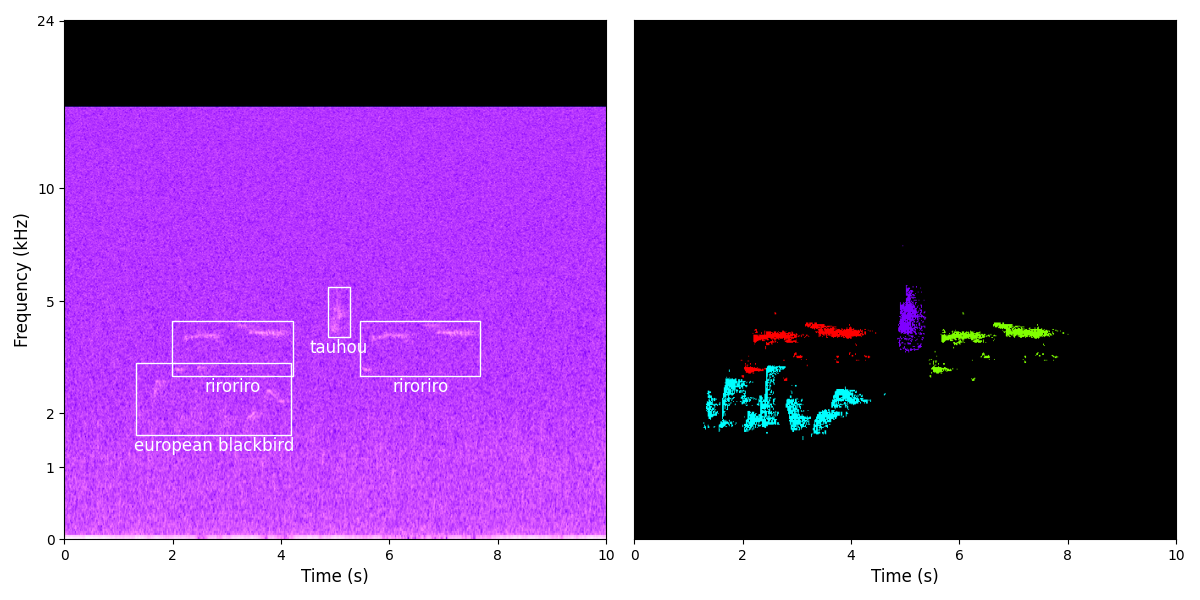
Read more about our method and evaluation in the preprint. You can use our framework yourself, try it out with the example dataset, and contribute to the project here.